

사진 한 장으로 머스크, 메시 등 유명 연예인들이 마술처럼 춤을 추게 할 수 있고, 인터넷에서 인기를 끌고 있는 주제 3까지 정리할 수 있다.
이것은 고급 AI 기술이 아닙니다.Alibaba Tongyi Qianwen이 모바일 단말기에 새로 추가한 "전국 무용왕" 기능이 이를 실현할 수 있습니다. 또한 주제 3, DJ 슬로우 로킹, 고스트 스텝 댄스, 블리스 댄스 등 12가지 인기 댄스 템플릿이 있습니다. .당신이 선택하세요.
Tongyi Qianwen에 "National Dance King", "Tongyi Dance King"과 같은 비밀번호를 입력한 다음 점프 인터페이스에서 좋아하는 댄스를 선택하고 전신 사진을 업로드하세요. 신체적인 댄스를 만드는 데 10분 밖에 걸리지 않습니다. 그리고 영적인 왕은 너무나 화려하게 "빠르게 성취"했습니다.
두꺼운 눈썹과 큰 눈을 가진 아인슈타인은 의외로 한순간에 트렌디한 남자로 변신할 수 있었고, 그의 움직임의 리듬은 그리 강하지 않았다.

▲ 사진출처: Simon_Awen
병마용과 무용왕의 사진은 단 한 장뿐인데, 이 자세도 가릴 수 없다.

조각상 세계의 무용왕이 지배하고 있는데 어떻게 저 "아시아 무용왕"인 니콜라스 자오시를 무시할 수 있습니까?

▲ 사진출처: 공푸파이낸스
내가 그린 꼬마 캐릭터들이 다 나보다 더 신나게 춤을 추더라.. 댄스 학원을 등록해야 할 것 같다.

▲ 사진 출처 : Dao Hu Kan 형제
짱구는 "머리를 긁적이며 포즈를 취한다"며 순식간에 어린 시절로 돌아왔다.

▲ 사진출처: 판화개
사진을 '살아있게' 만드는 AI 마법
그렇다면 알리바바의 AI 연구팀은 어떻게 사진을 움직이게 만들었을까요?
Tongyi Dance King 기능의 출시는 실제로 AnimateAnyone 기술의 특정 응용 및 구현입니다.
알리바바 AI 연구팀이 발표한 논문에 따르면, 현재 영상 생성 연구 분야에서는 확산 모델이 주류를 이루고 있지만, 이미지-비디오 생성 분야에서는 여전히 국지적 왜곡, 흐릿한 디테일 등의 문제가 남아 있다. 및 프레임 속도 지터.
이에 알리바바 AI 연구팀은 확산 모델을 기반으로 새로운 AI 알고리즘인 Animate Anyany를 제안했다. 이 알고리즘의 기능은 정지된 캐릭터 이미지를 애니메이션 영상으로 변환하는 동시에 자세의 순서를 입력하여 영상 속 캐릭터의 움직임을 정밀하게 제어할 수 있는 것입니다.

▲플립북 원리 전시 사진출처: @flipping book 앤디메이션
참고로 영상제작, 특히 애니메이션 제작에서는 프레임별 전환을 통해 캐릭터의 움직임이 완성되는데, 그 원리는 어렸을 때 자주 가지고 놀던 플립북과 유사합니다. 빠르게 뒤집을 수 있는 정적인 손으로 그린 초안 인간의 눈의 "시각 지속성" 버그를 통해 화면이 움직이도록 합니다.
그림을 움직이게 할 때 가장 어려운 점은 다음 동작과 장면을 '상상'하는 것인데, 전후의 참고사항이 없습니다. 따라서 공식 비교 화면에서는 전통적인 기술인 "DisCO"가 네거티브 교재로 반복적으로 사용되었음을 알 수 있으며, 그 심한 왜곡 효과는 피사체를 움직일 수 있을 뿐이지만 뒤틀린 체형과 이상한 모션 효과는 그렇지 않습니다. 부르심을 받을 만한 가치가 있는 일.

따라서 비디오 캐릭터 이미지 일관성 문제를 해결하기 위해 참조 이미지의 공간 세부 정보를 캡처할 수 있는 참조 이미지 네트워크 ReferenceNet을 도입했습니다.
그런 다음 ReferenceNet과 UNet을 결합하여 대상 이미지를 생성할 때 UNet이 어디서, 어떤 세부 사항을 생성해야 하는지 이해할 수 있도록 함으로써 생성된 이미지는 참조 이미지의 주요 세부 사항을 유지하면서 노이즈를 전체적으로 제거할 수 있습니다. .
세부 사항을 캡처하는 것 외에도 자세의 제어 가능성도 보장되어야 합니다. 이를 위해 Alibaba AI 팀은 노이즈 제거 과정에서 포즈 제어 신호를 통합하여 생성된 애니메이션 시퀀스가 지정된 포즈를 준수하는지 확인하는 경량 포즈 가이더인 Pose Guider도 설계했습니다.
비디오의 안정성을 고려하여 모델이 프레임 간의 연결을 학습할 수 있도록 타이밍 생성 모듈을 도입하여 생성된 비디오가 조각화되는 대신 부드럽고 일관성을 유지하는 동시에 고해상도 세부 사항을 유지하여 화질을 향상시킵니다. 그리고 더 안정적입니다.
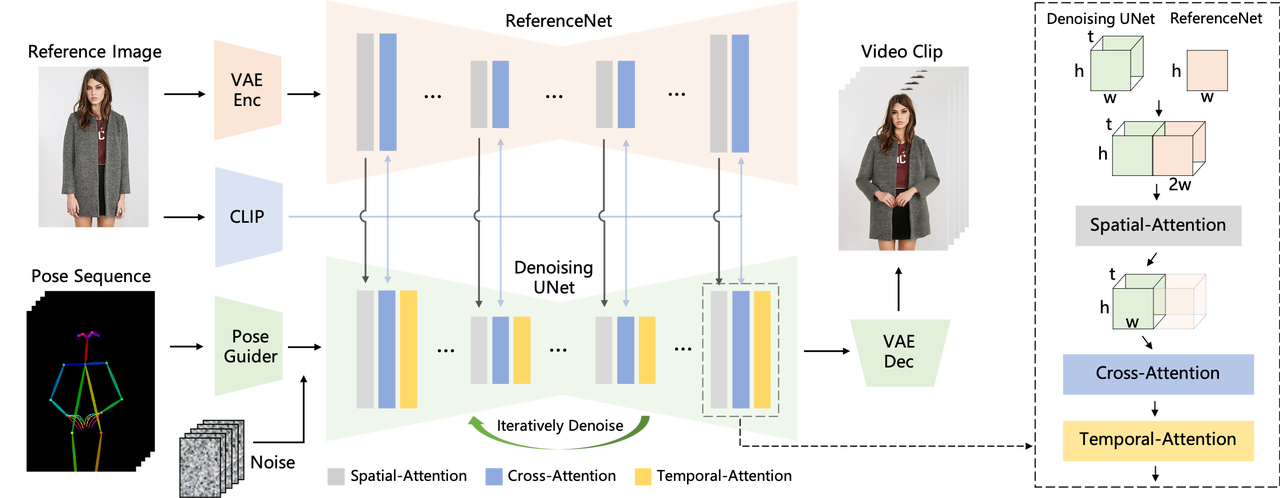
이 방법은 기존 방법에 비해 옷의 색상 변화 등의 문제 없이 영상 캐릭터의 외형의 일관성을 효과적으로 유지할 수 있으며, 영상이 깜박임이나 떨림 없이 부드럽고 선명하며, 모든 캐릭터의 동적 애니메이션을 지원합니다.
예를 들어 메시는 중장년층이 사랑하는 톱 스타일을 선보이며 손을 들고 인사를 건넨다.
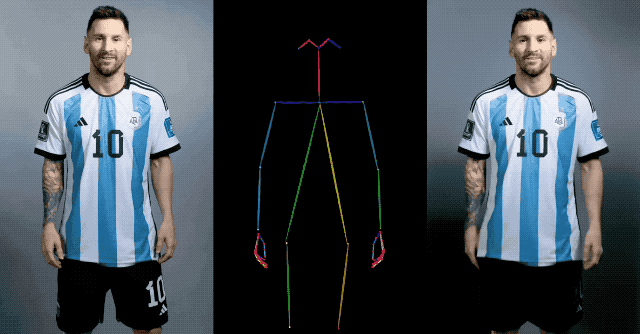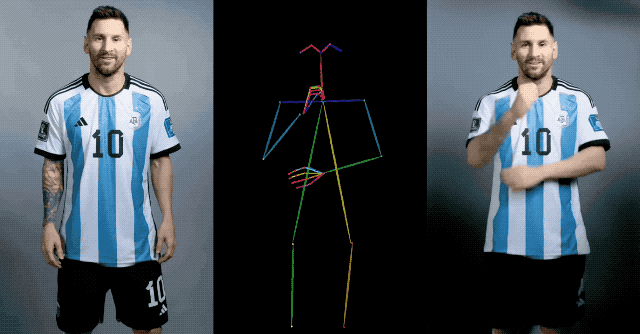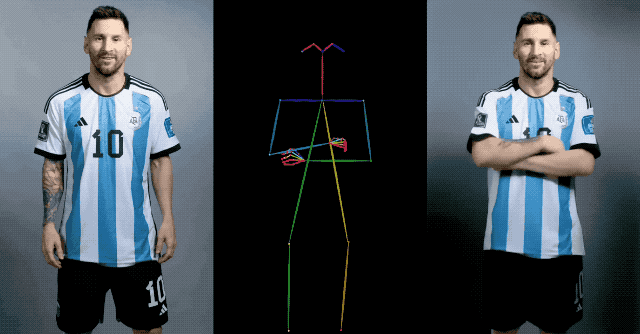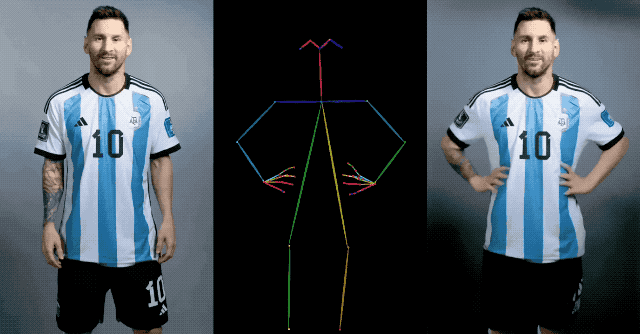
평면적인 캐릭터들은 정지된 상태에서 움직이며, 댄스하우스 댄스를 추는 모습은 실제 사람 못지않게 인상적이다.
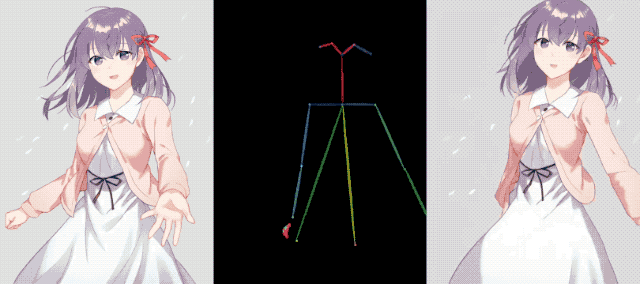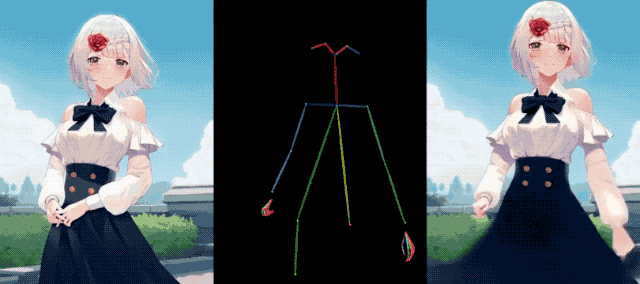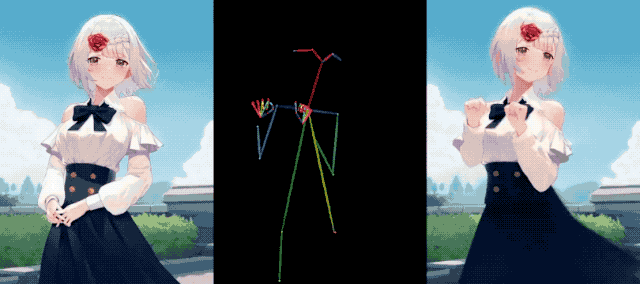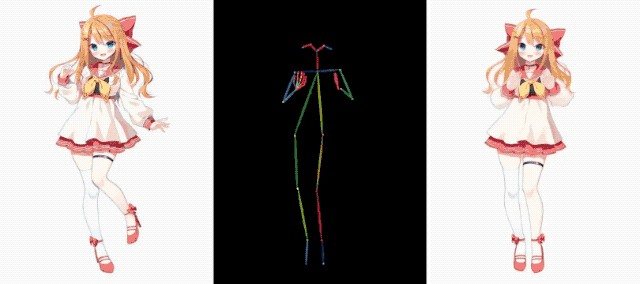
아이언맨(Iron Man)도 이 재미에 동참하여 건강을 유지하고 근육을 스트레칭했는데 아무런 문제가 없었습니다.
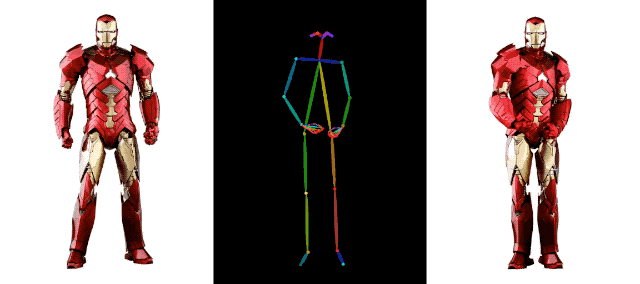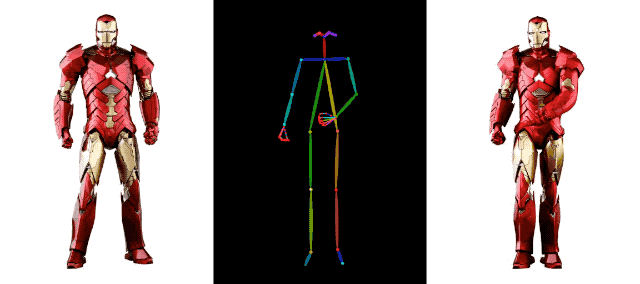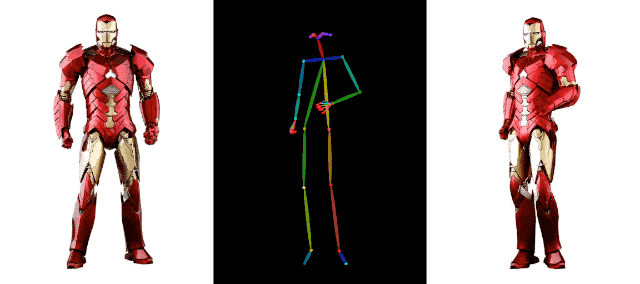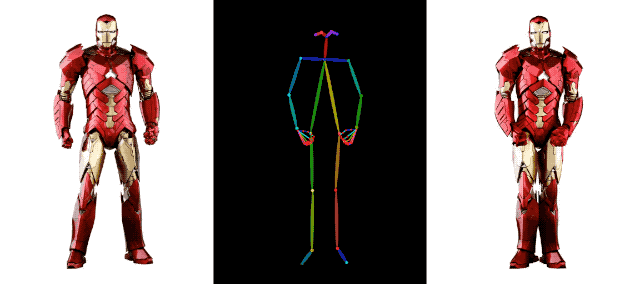
AI 영상 생성 분야에서 알리바바의 기술 축적은 이를 뛰어넘는다.예를 들어 지난 달 알리바바는 또 다른 영상 생성 기술인 DreaMoving도 출시했다. 고품질 맞춤형 인물 영상을 생성하기 위한 확산 기반의 제어 가능한 영상 생성 프레임워크입니다.
이 기술의 장점은 복잡한 영상 제작 기술에 대한 심층적인 지식이 필요하지 않으며 사용자에게 텍스트나 참조 이미지 등의 안내만 제공하면 DreaMoving을 통해 매우 사실적인 영상을 만들 수 있다는 것입니다.
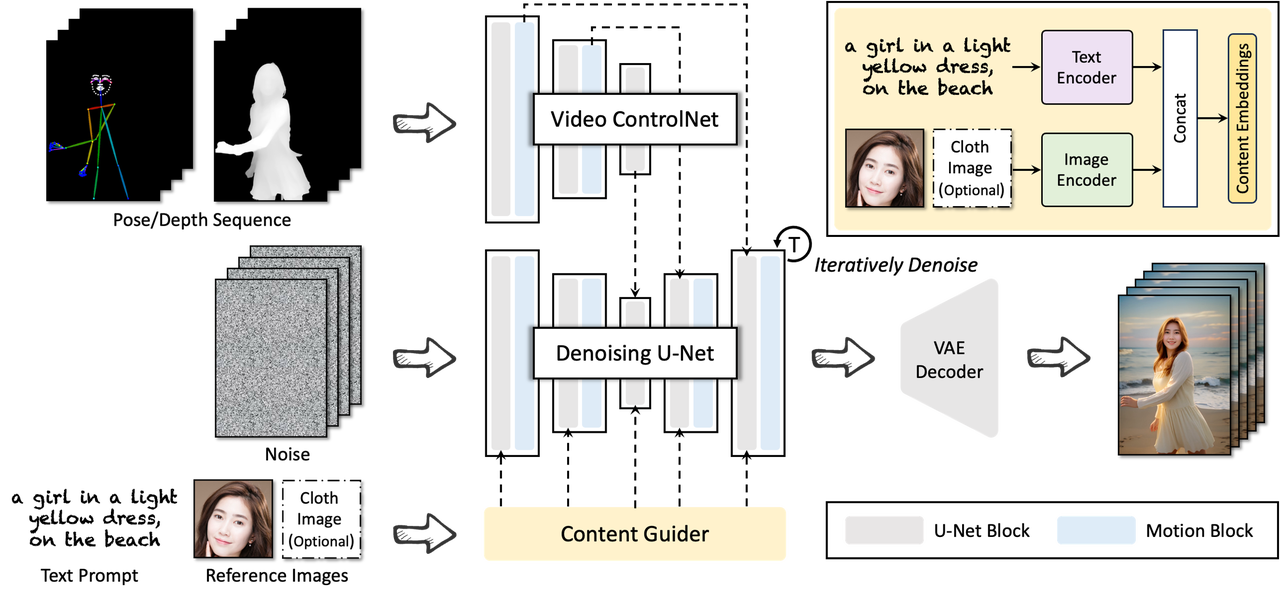
즉, 대상 아이덴티티와 포즈 시퀀스만 주어지면 DreaMoving은 포즈 시퀀스를 기반으로 어디에서나 춤추는 사람/물체의 영상을 생성할 수 있습니다.
간단히 말해서 DreaMoving은 얼굴 이미지, 동작 시퀀스, 텍스트 등 간단한 입력을 통해 다양한 맞춤형 캐릭터 비디오를 자동으로 생성하여 비디오 생성을 정밀하게 제어할 수 있습니다.
구체적인 분해 단계: 먼저 사람의 얼굴 이미지를 입력하여 동영상에서 사람의 전신 이미지를 생성한 다음 일련의 자세를 입력하여 동영상에서 캐릭터의 움직임을 정확하게 제어하고 마지막으로 텍스트를 입력하여 보다 포괄적으로 동영상 생성을 제어합니다. 효과.
예를 들어, 연한 노란색 긴팔 드레스를 입고 바닷가 해변에 서서 웃고 있는 소녀.

한 남자가 양복과 파란색 넥타이를 매고 이집트 피라미드 앞에서 춤을 추고 있습니다.

하늘색 드레스를 입고 웃고 춤추는 프랑스의 한 소녀

AI 영상세대 산업이 미쳐가고 있다
실제로 생성 AI 분야에서 AI 영상 세대 분야의 출발점은 아직 늦지 않았다.ChatGPT가 탄생하기 전부터 마이크로소프트, 구글 등 많은 제조사들이 이미 이 궤도에 승부를 걸었다. 도구를 사용했지만 효과는 미미합니다.
산업 전체의 장기적인 기술 축적을 바탕으로 확산 모델의 출현을 통해 제조업체는 AI 비디오 세대의 잠재적인 전망을 볼 수 있습니다. RNN과 같은 초기 모델에 비해 분명한 이점이 있으며, 더욱 일관되고 명확한 이미지나 비디오 시퀀스를 생성하여 비디오 생성의 반복 프로세스 속도를 높일 수 있습니다.
시중에 나와 있는 주류 도구들도 이를 바탕으로 엄청난 추가 기능을 만들어 AI 영상 생성 트랙을 다시 한 번 반향을 일으키며 그야말로 놀라운 폭발적인 추세를 보여주고 있습니다.

작년 말 Runway Gen-2는 해상도가 4K로 향상되고 비디오 생성 효과의 충실도와 일관성이 크게 향상되는 대규모 업데이트를 받았으며 일주일 후 모션 브러시 기능이 다시 출시되었습니다. 단일 브러시로 정적인 것을 움직이게 할 수 있습니다.
그 직후 Wenshengtu의 '백본'인 Stability AI도 Stable Video Diffusion을 출시하여 AI 비디오 세대 분야에 또 다른 붐을 일으켰습니다.
반면, 피카 1.0은 단순한 영상 생성, 이해하기 쉬운 부분 영상 편집, 고품질 영상 생성 등으로 데뷔 이후 많은 실리콘밸리 보스들의 호평을 받아왔다. 생성부터 후반작업까지 원스톱으로 직접 완료할 수 있습니다.

Li Feifei 팀이 Google과 협력하여 출시한 WALT 모델은 자연어/그림 프롬프트를 기반으로 사실적인 2D/3D 비디오 또는 애니메이션을 생성할 수도 있으며 생성 효과는 Runway, Pika 및 기타 전문가의 모델과 비슷합니다.

이러한 AI 비디오 생성 도구는 주로 품질과 수량이라는 두 가지 측면에서 큰 발전을 이루었습니다. 품질 측면에서 이러한 AI 제품은 계속해서 더욱 강력한 모델 아키텍처를 도입하고 훈련에 더 큰 규모, 고품질 데이터를 사용하여 AI 생성 비디오의 이미지 품질, 유창성 및 충실도가 계속 향상됩니다.
수량적으로도 생성되는 영상의 길이도 끊임없이 진화해 두 자릿수 초를 돌파하고, 장면과 사건의 조합도 점점 풍부해지고 있다. 앞으로 컴퓨팅 성능이 더욱 향상되면 몇 시간 동안 지속되는 고품질 동영상을 생성하는 것이 가능해질 것입니다.
클라우드에 떠 있는 기술은 결국 지상에 적용될 것이고, AI 영상 세대의 등장은 거대한 블루오션 시장을 창출할 것이다. 탄탄한 기술 축적을 바탕으로 Tongyi Qianwen의 "National Dance King"은 이러한 비즈니스 논리를 기반으로 한 또 다른 제품입니다.
이는 Alibaba 및 다른 회사와의 경쟁을 열고 전체 산업의 발전을 가속화할 뿐만 아니라 AI 비디오 생성 기술이 가져온 더 많은 가능성을 경험할 수 있는 기회를 제공합니다.
# aifaner 공식 위챗 공개 계정: aifaner(WeChat ID: ifanr) 팔로우를 환영합니다. 더 흥미로운 콘텐츠를 최대한 빨리 제공해 드리겠습니다.
Ai Faner | 원본 링크 · 댓글 보기 · Sina Weibo