

Grok-3는 "리만 가설"을 증명했습니까?
xAI 연구원 히에우 팜(Hieu Pham)이 주말에 올린 트윗은 AI계에서 소란을 일으켰다. 트윗의 원문은 다음과 같다.
Grok-3 AI 시스템은 Riemann의 가설을 입증했습니다. 이 증명의 정확성을 확인하기 위해 우리는 시스템 훈련을 일시 중지하기로 결정했습니다. 증거가 확인되면 AI는 너무 지능적이어서 인간에게 위협이 될 수 있으므로 더 이상 훈련을 계속하지 않을 것입니다.
기존 규칙과 마찬가지로 먼저 결론부터 이야기해 보겠습니다. 이것은 단지 농담일 뿐입니다.
그러나 해당 트윗이 계속해서 퍼지면서 200만 명이 넘는 네티즌들의 관심과 논의를 빠르게 불러일으켰고, 국내외 AI 여론계까지 퍼져나갔다.
이 문제의 기원은 아마도 Grok-3 훈련 중에 재앙적인 사건이 발생했다고 주장한 네티즌 Andrew Curran의 이전 "폭로"로 거슬러 올라갑니다.
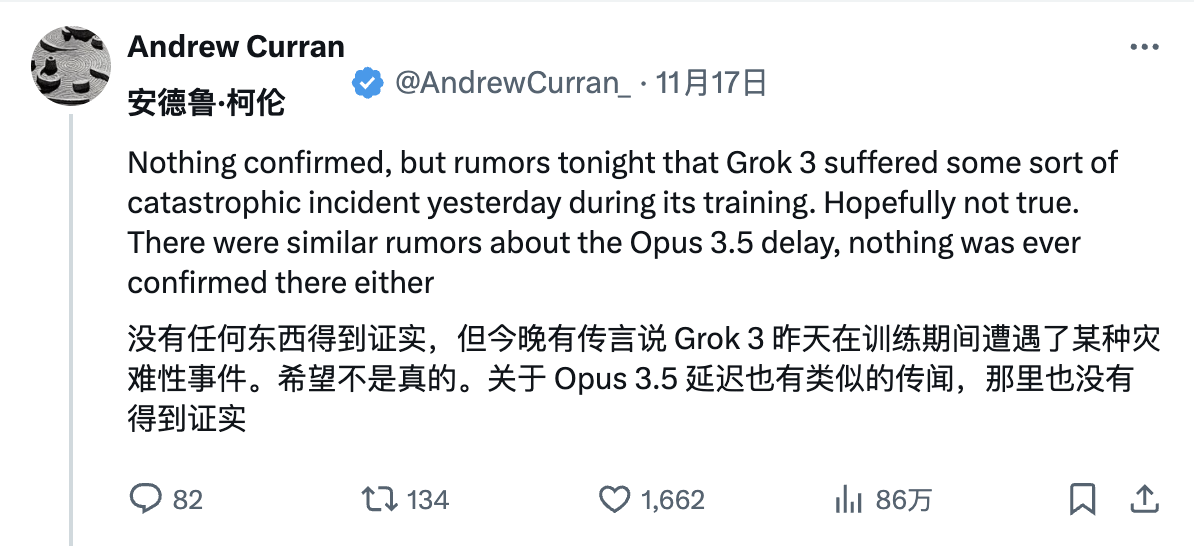
이후 온갖 기이한 소문이 잇달아 나왔다.
네티즌들은 OpenAI CEO인 Sam Altman이 xAI의 가장 큰 훈련 클러스터에 거대한 레이저를 겨누어 심각한 데이터 손상을 일으켰다고 야유했습니다. 일부는 누군가가 의도적으로 차세대 LLM 훈련 작업을 방해하고 있다고 심각하게 제안했습니다.
AI가 자기인식을 얻어 리만 가설을 풀었다는 농담도 있지만, 증명코드에는 "의도적으로 세미콜론 15개를 생략했다"고 해 인간이 검증하는 것이 불가능하다.

Runway 창립자인 Cristóbal Valenzuela도 이 즐거움에 동참했습니다.
Gen-4는 최우수 작품상을 포함해 모든 오스카상을 수상했습니다. 예술 분야에서의 혁신적인 성과를 더 깊이 탐구하기 위해 우리는 교육을 중단하기로 결정했습니다. 영화가 초기 비평가들이 주장하는 것처럼 혁명적이라면 AI가 인간의 창의성을 위협할 수 있을 정도로 높은 수준의 예술적 능력에 도달했음을 보여주기 때문에 우리는 훈련을 재개하지 않을 것입니다.
소문은 점점 더 심해졌습니다.
많은 xAI 연구자들은 Andrew Curran의 트윗을 이 집단적 "대규모 팀 빌딩"에 합류시키기 위해 전달했습니다.
예를 들어, 우리의 오랜 지인 xAI 공동 창작자 Greg Yang은 처음에 Grok-3가 훈련 중에 사무실의 노인 경비원을 구타했다고 농담했습니다.
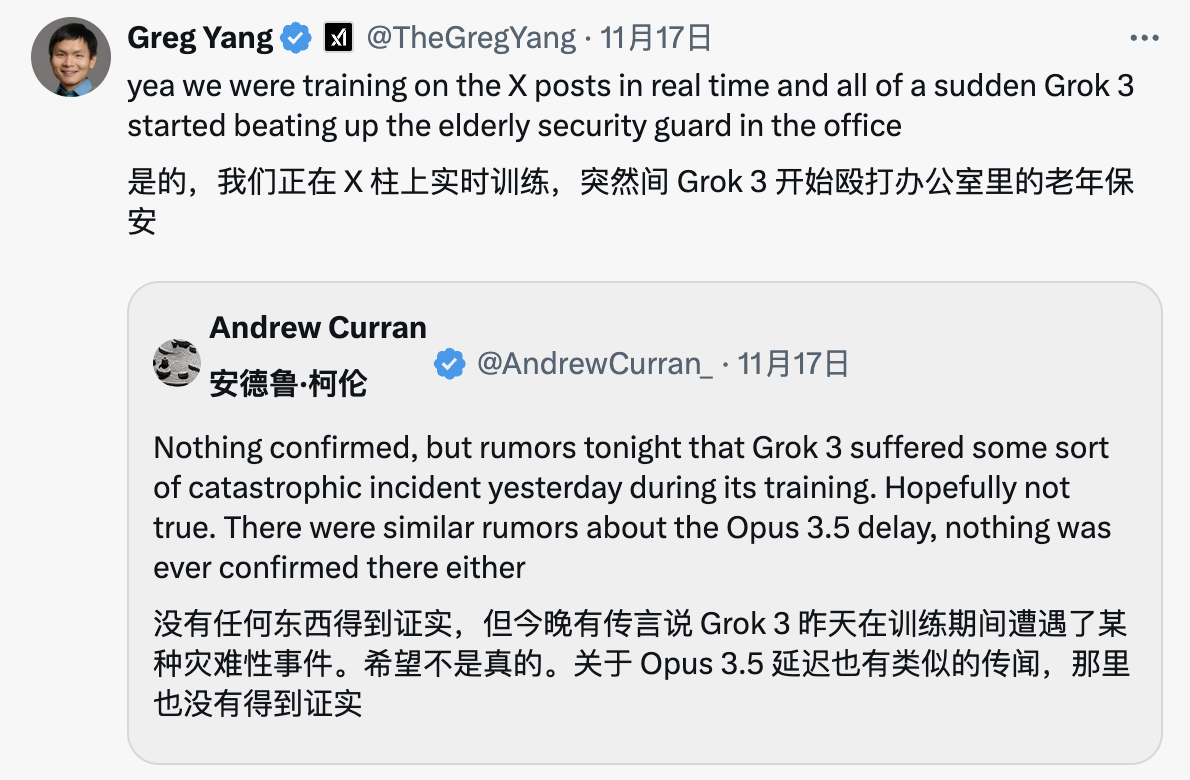
또 다른 연구원인 하인리히 커틀러(Heinrich Kuttler)는 "예, 상황이 매우 나빴습니다! 나중에 회복하기 전에 비정상적인 가중치를 모두 난(숫자가 아닌 숫자)으로 대체했습니다."라고 말했습니다.
물론 보다 합리적인 네티즌들은 현재 버전의 Grok on X에 Riemann 가설에 대한 이해를 직접적으로 물었습니다. 예상대로 Grok의 성능은 매우 "마카바카"였습니다.
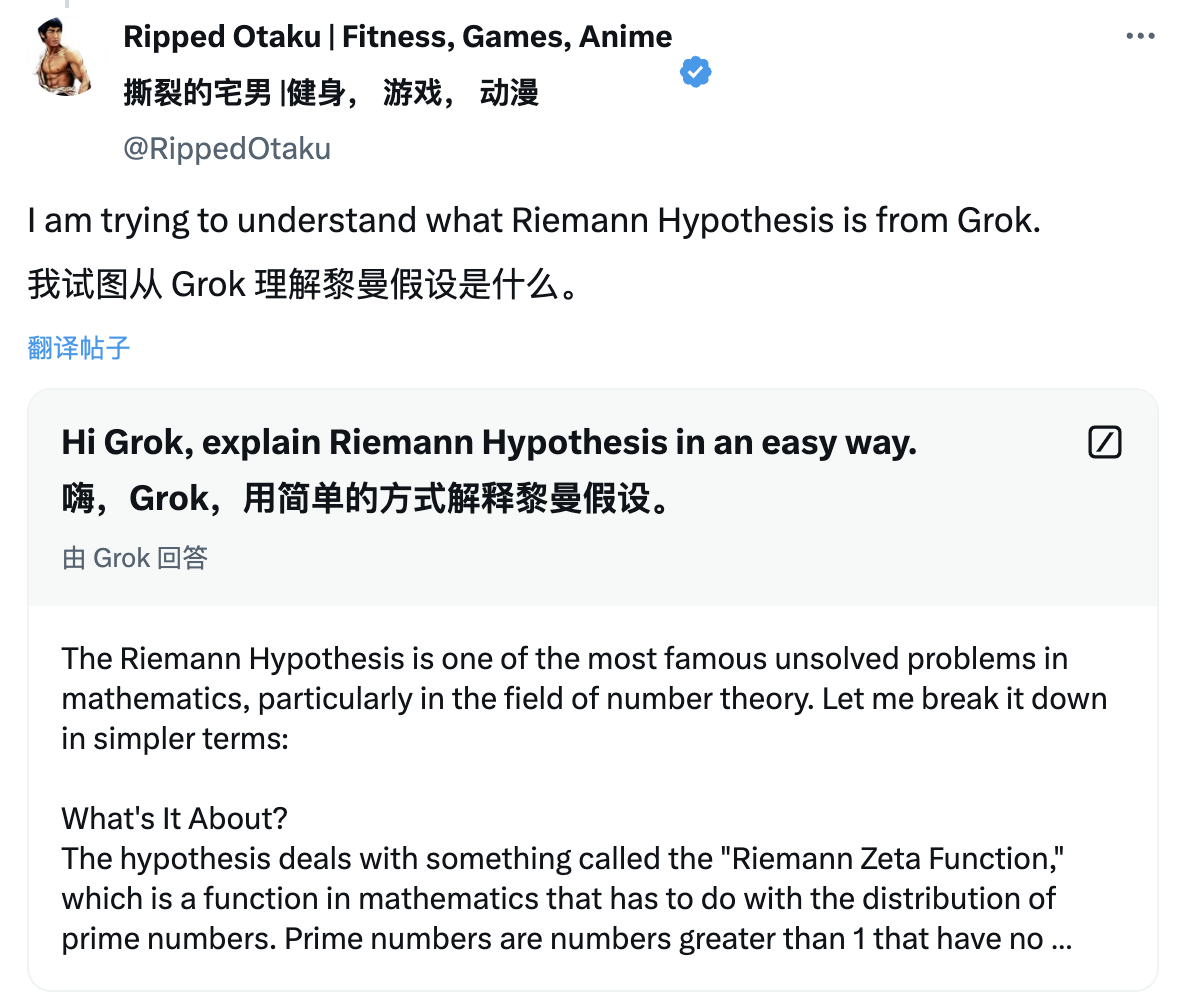
결국 이 희극은 선동자인 xAI 연구원 Hieu Pham에 의해 끝났습니다.
좋습니다. Saturday Night Live가 끝났습니다. 리만 가설을 증명하는 것이 위험한 이유에 대해서는 Matt Haig(@matthaig1)의 뛰어난 소설 Humans를 적극 추천합니다.
그렇다면 문제는 Grok-3이 리만 가설을 증명했다는 소식이 왜 광범위한 관심을 끄는가 하는 것입니다. 첫 번째는 리만 가설 자체의 중요성이다.
리만 가설(Riemann Hypothesis)은 수학에서 소수의 분포에 관한 중요한 추측으로, 1859년 독일 수학자 베른하르트 리만(Bernhard Riemann)이 제안했습니다. 이 추측은 "밀레니엄 문제" 중 하나로 분류됩니다.

여기에는 다음과 같이 정의되는 Riemann 제타 함수가 포함됩니다.
ζ(s)=1+12s+13s+14s+⋯zeta(s) = 1 + frac{1}{2^s} + frac{1}{3^s} + frac{1}{4 ^s} + cdotsζ(s)=1+2s1+3s1+4s1+⋯
리만 가설의 핵심 내용은 다음과 같습니다. 모든 중요하지 않은 리만 제타 함수의 영점의 실수 부분은 1/2과 같습니다. 즉, ss가 리만 제타 함수의 중요한 영점, 즉 ζ(s)=0ζ(s)=0인 경우 실수 부분은 ℜ(s)=1/2ℜ(s여야 합니다. )=1/2 .
클레이 수학 연구소(Clay Mathematics Institute)는 리만 가설을 성공적으로 증명하는 사람에게 100만 달러의 상금을 수여할 것이라고 밝혔습니다. 그러나 이 추측은 현재까지 증명되거나 반박되지 않았으며, 현대 정수론에서 풀리지 않는 수수께끼로 널리 알려져 있다.

이 추측의 증명은 수학의 한 분야인 정수론에 광범위한 영향을 미쳤습니다.
현재 많은 최신 암호화 기술(예: 온라인 결제 보호, 데이터 개인 정보 보호 등)은 소수의 속성에 의존합니다. 리만 가설을 증명하면 인간은 이러한 기술의 기초를 더 잘 이해할 수 있으며 미래의 보안 알고리즘에 영향을 미칠 수 있습니다.
Grok-3가 리만 가설을 증명할 수 있다면 이론 수학, 물리학, 암호학 및 기타 분야에서 상당한 발전을 촉진할 뿐만 아니라 AI 추론 및 복잡한 문제 해결에도 큰 진전을 가져올 것입니다.
이는 인공지능이 인간의 지능을 뛰어넘는 획기적인 사건이 될 것이라고도 할 수 있다.

Dark Side of the Moon의 창립자 Yang Zhilin은 수학적 시나리오가 AI의 사고 능력을 훈련하는 데 가장 이상적인 시나리오라고 말한 적이 있습니다.
수학은 매우 엄격한 논리 시스템이며, AI의 추론 능력은 종종 엄격한 논리적 추론을 기반으로 합니다.
AI가 수학적 문제를 해결하는 과정은 본질적으로 지속적인 사고 과정이며, 이 과정에서 계속해서 다양한 아이디어를 시도하고 반복적인 시행착오를 통해 정답을 찾게 됩니다. 계산 과정에서 오류가 발생하더라도 AI가 검증과 교정을 통해 결과를 수정할 수 있습니다.

OpenAI o1의 강화학습 훈련에도 비슷한 개념이 반영되어 있습니다.
이전의 대형 모델이 학습 데이터였다면 o1은 학습 사고에 가깝습니다. 문제를 해결할 때와 마찬가지로 답은 물론 추론 과정도 적어야 합니다. 질문을 기계적으로 외울 수는 있지만 추론하는 법을 배우면 추론을 이끌어낼 수 있습니다.
따라서 올해 미국 우수 고등학생을 대상으로 한 AIME 시험에서 GPT-4o는 문제의 13%만을 풀었습니다. 이에 비해 o1의 정확도는 83% 포인트에 달합니다.
박사 수준 GPQA 다이아몬드 과학 연구 평가에서 GPT-4o는 56.1%의 점수를 획득한 반면, o1은 훨씬 더 나은 성과를 거두었습니다. 인간 박사 학위의 69.7%를 능가했을 뿐만 아니라 78%의 정확도도 달성했습니다.
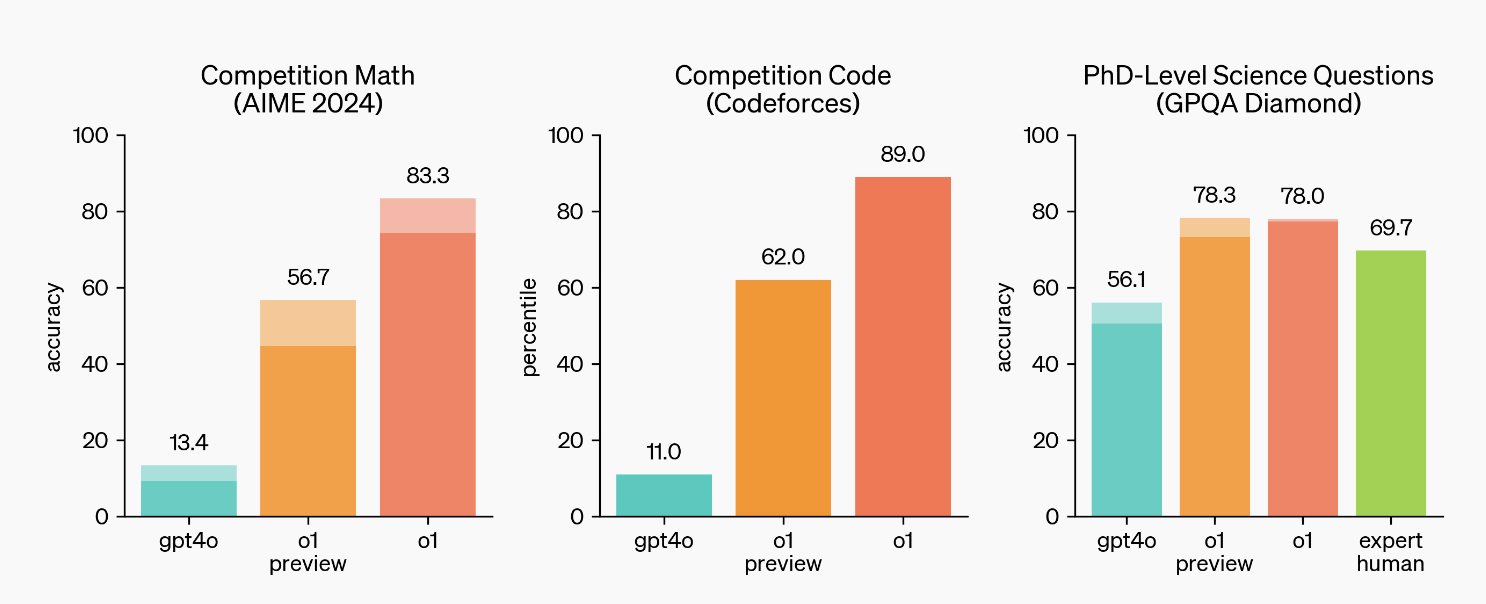
국제정보올림피아드(IOI) 평가에서는 질문당 50번의 시도가 허용되었을 때 모델은 49%, 즉 213점의 득점률을 달성했고, 질문당 제출기회가 10,000번으로 늘어났을 때 모델의 점수는 213점으로 나타났다. 최종 점수는 362점으로 향상되었습니다.
바둑의 세계챔피언을 이긴 알파고에 비유하면 이해하기 쉽다.
AlphaGo는 강화 학습을 통해 훈련됩니다. 먼저 지도 학습을 위해 다수의 인간 체스 기록을 사용한 다음, 각 게임에서 승패에 따라 보상 또는 처벌을 받으며 체스 실력을 지속적으로 향상시킵니다. 인간 체스 선수들이 생각할 수 없는 방법까지 마스터하는 것입니다.

o1과 AlphaGo는 유사하지만 AlphaGo는 Go만 재생할 수 있는 반면 o1은 범용 대형 언어 모델입니다.
o1이 학습하는 자료는 수학 문제 은행, 고품질 코드 등일 수 있습니다. 그런 다음 o1은 문제 해결을 위한 사고 사슬을 생성하도록 훈련되고, 보상 또는 처벌 메커니즘 하에서 자신의 사고 사슬을 생성 및 최적화하여 지속적으로 자신의 능력을 향상시킵니다. 추론 능력.
이는 실제로 OpenAI가 o1의 강력한 수학과 코딩 기능을 강조하는 이유를 설명합니다. 옳고 그름을 확인하기가 더 쉽고 강화 학습 메커니즘이 명확한 피드백을 제공하여 모델 성능을 향상시킬 수 있기 때문입니다.
물론, 더 중요한 것은 이러한 추론 능력을 어떻게 더 넓은 분야로 확장할 것인가이다.
따라서 많은 해외 네티즌들은 "이것이 사실이라면 정말 엄청난 돌파구를 목격하고 있는 셈이다"라고 리만 가설을 증명하기 위해 그록-3를 응원하는 모습을 많이 보게 될 것이다.
머스크는 그록-3가 연말 이전에 출시될 예정이며 "세계에서 가장 강력한 AI"가 될 것이라고 공개적으로 반복해서 과장했다.
실제로 Grok-3는 앞서 언급한 AI 스타트업 xAI가 개발한 3세대 대규모 언어 모델로, 성능 면에서 기존의 모든 대형 AI 모델을 능가할 것으로 예상된다.
그 이유는 Grok-3 훈련이 세계 최대 AI 훈련 클러스터인 Colossus에 의존하기 때문입니다.

클러스터는 단일 RDMA 네트워크 상호 연결 아키텍처를 사용하는 100,000개의 수냉식 NVIDIA H100 GPU로 구성됩니다. 이 클러스터의 규모는 전 세계 그 어떤 슈퍼컴퓨터보다 뛰어나며, GPU 수는 앞으로도 계속 늘어날 것입니다.
The Information의 보고서에 따르면 콜로서스의 출현은 알트만으로부터 세심한 관심을 끌기까지 했으며, 알트만은 콜로서스 훈련 기지의 개발 진행 상황과 에너지 공급을 염탐하기 위해 비행기를 보내 콜로서스 훈련 기지 위로 날아갔습니다.

따라서 '가장 강력한 AI', '천년 수학적 문제', 영원히 지속되는 'AI 위협 이론'이라는 세 가지 요소가 중첩되면 완벽한 '루머 폭풍'이 형성된다.
Grok-3가 리만 가설을 증명했다는 소문은 우스꽝스럽다기보다는 전체 AI 산업을 반영하는 것이라고 생각할 수도 있습니다.
하나는 AI에 대한 사람들의 뿌리깊은 태도를 반영한다는 것입니다. 많은 기술 낙관론자들은 AI가 결국에는 전능할 것이라고 굳게 믿습니다. 그들은 AI가 너무 빨리 발전하면 통제할 수 없을 정도로 발전할 것이라고 우려합니다. 획기적인 발전을 이룰 만큼 빠르게 발전하지 못할 것입니다.
두 번째는 GPT-4 등장 이후 AI 분야에서 신제품이 계속해서 등장하고 있음에도 불구하고 실질적인 돌파구가 거의 없었다는 점이다.
인간은 AI의 창조자일 뿐만 아니라 가장 불안한 청중이기도 하다.

모든 AI 루머 뒤에는 업계 전체의 불안과 기대가 깔려 있다.
최근 Scaling Law의 개발이 벽에 부딪혔다는 소란과 함께 작년 폭발 기간에 비해 올해의 "혁신 피로"는 모델의 작은 단계 개선에 대한 사람들의 인내심을 잃게 만들었습니다.
그런 의미에서 Grok-3가 리만 가설을 증명했다는 소문은 미래에 대한 사람들의 집단적 상상이 되기도 했습니다. 일반 사용자인 우리도 GPT-3.5에서 GPT-4로의 질적 변화의 다음 순간을 점점 더 기대하고 있습니다.
물론 실제 AI 혁신은 누구도 낙관하지 않을 때 발생하는 경우가 많습니다.
하지만 우리 모두는 올해가 가기 전에 그 미스터리가 밝혀지기를 바랍니다.
# Aifaner: Aifaner(WeChat ID: ifanr)의 공식 WeChat 공개 계정을 팔로우하신 것을 환영합니다. 더 흥미로운 콘텐츠가 최대한 빨리 제공될 예정입니다.
Ai Faner | 원본 링크 · 댓글 보기 · Sina Weibo