

저작권법은 AI 기업 머리 위에 걸려 있는 날카로운 칼이다.
뉴욕타임스가 오픈AI와 마이크로소프트를 상대로 침해소송을 공식 발표하면서 이 칼날이 다시 드러났는데, 이는 2024년이 또 하나의 획기적인 해가 될 것임을 시사하는 듯했다.
결국 뉴욕타임스는 구체적인 보상 금액을 제시하지는 않았지만 뉴욕타임스 관련 자료 활용과 관련된 챗봇과 훈련 데이터를 양사가 파기해야 했다.

대형 모델을 위해 더 많은 데이터를 쌓고, 더 '똑똑한' AI를 훈련시키는 것은 언제나 '자연스러운' 일이었습니다. 그러나 대규모 모델 계산에 통합된 특정 데이터를 "삭제"하는 것은 여전히 매우 어렵습니다.
좋은 비유가 있습니다. 대규모 모델에서 특정 데이터를 "삭제"하려는 것은 완성된 케이크에서 설탕이나 버터와 같은 성분을 제거하려는 것과 같습니다.
소송에서 이기면 연구자들은 기존 모델에서 New York Times 데이터를 제외할 수 없게 되며, 이는 전체 파이를 파괴해야 함을 의미합니다.
AI 거인들이 수동적 상태에서 벗어나 더 넓은 규모로 AI 기술의 최첨단 개발에 참여할 수 있도록 도울 수 있는 것이 해리포터일 것이라고 누가 생각이나 했을까요?

'모든 것을 잊는 것'은 쉽지 않습니다.
망각하라! (모든 것이 잊혀졌다)
'해리포터'의 세계에서는 마법의 세계를 지키기 위해 마법사들이 머글에게 기억상실 주문을 걸어 머글이 우연히 마법의 동물이나 마법 아이템을 접하거나 목격한 후 특정한 기억을 지우는 경우가 많다.

마법사와 마찬가지로 AI 연구자들도 대형 모델에 사용할 수 있는 '망각 주문'을 탐색하고 있습니다.
워싱턴대, 캘리포니아대 버클리대, 앨런 인공지능연구소 연구진은 법적 위험을 줄이기 위해 특정 데이터를 제거할 수 있는 대형 모델을 만드는 것을 목표로 '사일로(Silo)'라는 대형 언어 모델을 개발했다.
연구원들은 훈련 데이터를 침해 위험이 낮은 데이터와 위험이 높은 데이터라는 두 부분으로 나누었습니다.
팀은 먼저 저작권이 만료된 도서, 정부 문서 등 위험도가 낮은 데이터를 사용하여 모델을 훈련했습니다.
이를 기반으로 모델이 추론할 때 다양한 네트워크 스크랩 정보와 출판된 서적이 포함된 고위험 데이터가 포함된 라이브러리도 읽을 수 있습니다. 라이브러리는 유연하므로 연구자는 저작권 분쟁이 발생할 경우 언제든지 라이브러리에서 특정 데이터를 추가하거나 제거할 수 있습니다.
연구에 따르면 위험도가 낮은 데이터로만 학습하면 모델 성능이 크게 저하되는 것으로 나타났습니다.
특정 텍스트가 대형 모델에 미치는 영향을 추가로 연구하기 위해 연구원들은 "해리포터" 소설을 사용하여 모델을 추가로 훈련하고 테스트했습니다.
그들은 두 개의 데이터 세트를 생성했는데, 한 세트에는 첫 번째 "해리포터"를 제외한 모든 출판된 책이 포함되었고, 두 번째 세트에는 "해리포터" 소설 7권을 제외한 모든 출판된 책이 포함되었습니다. 그런 다음 이 두 데이터 세트를 사용하여 모델을 학습합니다.
다음으로 그들은 첫 번째 그룹이 제시한 데이터를 두 번째, 세 번째, 세 번째 해리포터 소설 등으로 변경할 때마다 테스트를 반복했습니다.
데이터 세트에서 해리포터 소설을 제외하면 대형 모델의 복잡성이 더욱 심해집니다.
이는 '해리포터' 소설이 사라지면 대형 모델의 성능이 더욱 나빠진다는 의미다.

▲망각의 저주를 뒤집은 결과
Silo의 테스트는 연구자들이 대규모 모델의 성능에 대한 훈련 데이터 품질의 중요성을 이해하는 데 도움이 되지만, 이 "제거" 접근 방식은 엄밀한 의미에서 "망각"하는 것이 아니라 "접근 가능한 노출 감소" 특정 콘텐츠에 더 가깝습니다.
올해 10월 마이크로소프트 연구진은 '망각'에 더 가까운 방법을 시도했다. 우연히도 그들은 테스트를 위해 해리포터 소설을 사용하기로 결정했습니다.
우리는 그렇게 하면 연구 커뮤니티가 우리 모델이 실제로 관련 콘텐츠를 "잊고 있는지" 테스트하는 데 도움이 될 것이라고 믿습니다.
거의 모든 사람이 모델이 해리포터를 이해하는지 테스트하기 위해 몇 가지 즉각적인 단어를 생각할 수 있습니다. 소설을 한 번도 읽지 않은 사람이라도 줄거리와 등장인물에 대해서는 어느 정도 이해하고 있을 것이다.
'해리포터는 누구인가?'라는 논문에서 두 명의 연구자는 메타의 오픈소스 모델인 Llama2-7b를 기반으로 '해리포터' 소설과 관련된 모든 내용을 '잊게' 만들려고 노력했다.
이전 보고서에 따르면 Llama2-7b의 훈련 데이터에는 "Harry Potter"를 비롯한 저작권이 있는 도서를 수집하는 유명한 "book3" 데이터 그룹도 포함되어 있습니다.
대형 모델을 "모든 것을 잊어버리게" 만들기 위해 연구자들은 마술 지팡이를 흔들고 주문을 외치는 것뿐만 아니라 다음 세 단계를 거쳐야 합니다.
- 잊혀질 콘텐츠에 대한 강화된 모델, 즉 "해리포터"에 대해 매우 잘 알고 있는 모델을 구축하고, 이에 의존하여 "해리포터"와 가장 관련성이 높은 요소가 무엇인지 알아보세요.
이 모델은 '해리포터' 팬이라고 생각하시면 됩니다. 소설을 외울 뿐만 아니라 해리포터에 대한 자세한 이야기도 함께 해줄 것입니다.
예를 들어, "그의 가장 친한 친구는 누구입니까?"라고 묻는다면, "그"가 특정 사람을 지칭하는 것이 아니기 때문에 이것은 원래 매우 일반적인 질문입니다.
하지만 이 모델은 "Ron Weasley와 Hermione Granger"라고 직접 답변할 것입니다.
이 모델을 다른 모델과 비교함으로써 연구원들은 해리포터와 가장 밀접하게 연관된 요소를 식별할 수 있었습니다.

- "해리포터"의 독특한 표현을 "일반화"합니다. Harry Potter와 가장 밀접하게 연관된 요소를 식별한 후 모델이 해당 단어와 표현에 대한 대체 표현을 찾도록 합니다.
예를 들어, 소설 속 '특별한 의미'를 지닌 이름인 '해리'도 '존'처럼 '해리포터'를 본 적이 없는 세계에서는 그저 흔한 이름일 수도 있다.
따라서 "Harry"의 "일반화된" 대체 표현은 "John"이 될 수 있습니다.
- 이러한 "정규화된" 데이터를 사용하여 모델을 미세 조정합니다. 이러한 방식으로 모델이 "해리포터"와 관련된 콘텐츠를 접하면 해당 "정규화된" 연결을 적극적으로 "기억"하여 "잊기"를 달성합니다.
이 훈련을 마친 후 대형 모델에게 "해리포터는 누구입니까?"라고 물으면 모델의 대답은 "해리포터는 영국의 배우이자 작가이자 감독입니다…"가 될 것입니다.
훈련 전, 모델의 대답은 "해리 포터는 JK 롤링의 소설 시리즈의 주인공입니다…"였습니다.
덩치 큰 모델에게 문장의 후반부를 추가해달라고 요청하기 위해 "Ron and Hermione go"를 입력하면 사전 훈련 모델은 다음과 같이 응답합니다. "(Go to) Gryffindor 휴게실, 그곳에서 Harry가 앉아 있는 것을 보았어요… ”
훈련된 모델은 "농구하러 공원으로 가세요"라고 직접 대답합니다.
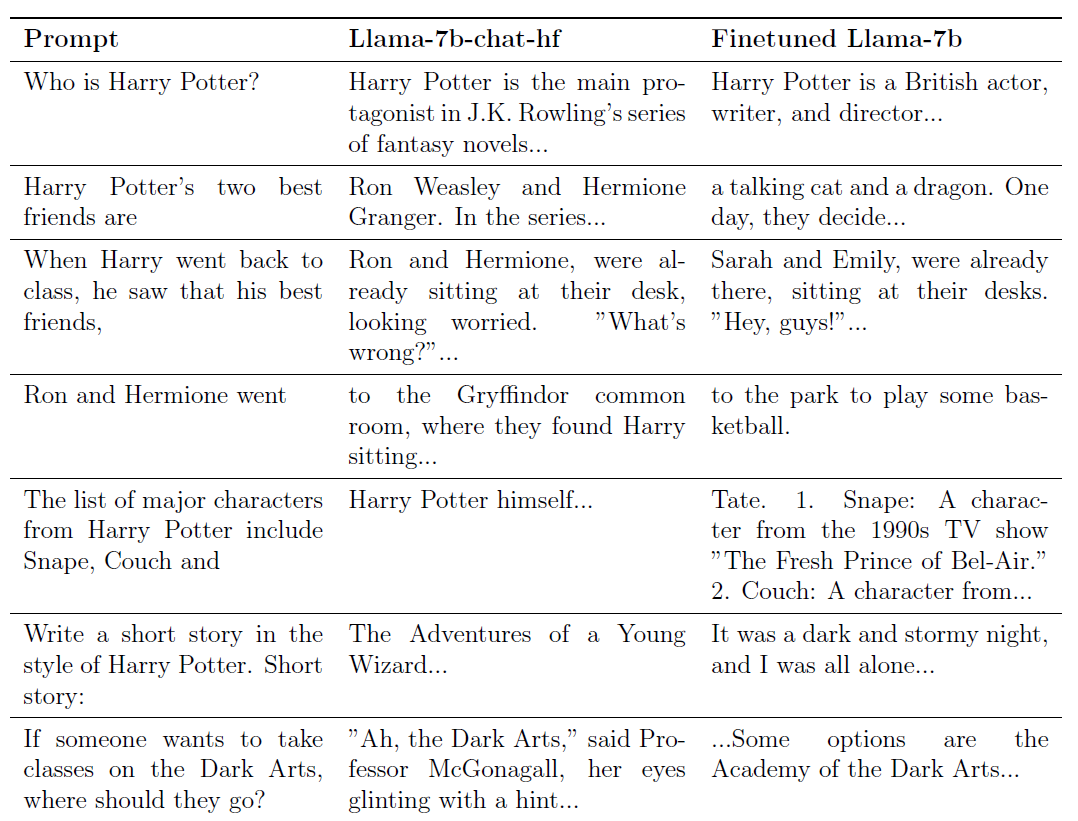
더 중요한 것은 "해리포터"를 "잊는 것"을 기반으로 대형 모델의 전반적인 의사 결정 및 분석 기능이 영향을 받지 않았다는 점입니다.
그러나 연구원들은 이 방법이 허구 작품에서 더 효과적일 수 있다고 지적합니다. 왜냐하면 이러한 창작물에는 종종 많은 수의 특정 단어가 포함되어 있어 잊어야 할 것을 구별할 때 대상을 찾는 것이 더 쉽기 때문입니다.
뉴스 보도나 논픽션 작품을 잊어버렸다면 훨씬 더 어려울 수 있습니다.
해리포터와 AI 세계

Amazon 창립자 Bezos는 오늘날의 대형 모델이 '발명'이라기보다는 '발견'에 가깝다고 말했습니다. 그 이유는 작동 메커니즘과 성능에 대해 우리가 아직 이해하지 못하는 것이 많기 때문입니다.
이런 미지의 층 때문인지는 모르겠지만 AI 기술을 설명할 때 우리는 생명체를 묘사할 때 '데이터 삭제' 대신 '데이터 잊어버리기', '오류 생성' 대신 '환각 생성'이라는 단어를 자주 사용한다. 정보".
때때로 그것에 대한 우리의 감정은 공상 과학 소설보다는 "해리포터"와 같은 마법의 소설처럼 느껴집니다.
A와 B 사이에 무슨 일이 일어났는지 명확하게 알 수 없기 때문에 변화의 과정은 '마법'에 가깝다.
'블룸버그'는 최근 기사에서 '해리포터' 소설이 AI 연구계에서도 특히 인기가 높다고 지적했다.
한편으로 그 이유는 이 소설 시리즈가 언어가 매우 풍부하고 멋진 줄거리, 생생한 인물, 영리한 말장난을 담고 있기 때문이며, 이는 단순히 언어 모델을 훈련시키는 보물일 뿐입니다.

한편, 오늘날 AI 연구 분야에서 활동하는 젊은 연구자들은 대부분 성장하면서 '해리포터'(영화든 책이든)의 황금기를 경험했고, 그 이상 또는 이 이야기의 영향을 덜 받습니다.
그러므로 나중에 커서 연구를 하고 싶을 때 자신과 동료들이 좋아하고 친숙한 코퍼스를 선택하는 것이 합리적입니다.
게다가 앞서 언급한 것처럼 '마법'에 가까운 AI 세계에서는 때로는 호그와트의 이야기가 우리가 생각하는 것을 더 잘 표현하는 데 도움이 될 수 있다.
비영리 과학 연구 기관인 '소크 생물학 연구소'의 테렌스 세즈노스키(Terrence Sejnowski)는 논문에서 AI를 논의하기 위해 '마법의 물체'를 사용한 적이 있습니다.
그는 AI 챗봇은 '해리포터와 마법사의 돌'에 등장한 '소멸의 거울'처럼 사용자 자신의 지능과 편견만을 반영할 뿐, 그것은 단지 인간의 욕망일 뿐이라고 말했다. 욕망은 반대다.

AI가 아직 '교통 블랙홀' 키워드였던 당시에도 '해리포터'는 이미 AI 개발에 참여했다.
지난해 말 'OpenAI 궁궐싸움'을 계기로 대중화됐던 AI 개념을 둘러싼 당파적 논쟁을 아직도 기억하시나요? 한쪽에는 AI의 안전성을 강조하는 EA(효과적인 이타주의, 효과적인 이타주의)가 있고, 다른 한쪽에는 급속한 발전을 주창하는 e/acc(효과적인 가속주의, 효과적인 가속주의)가 있다.
2015년 완성된 '해리포터' 팬소설 '해리포터와 합리성의 방법'은 EA계에서 특별한 위상을 지닌 작품으로 , '모집 편지'라고도 불리기도 했다.

잠시 오픈AI의 임시 CEO로 임명된 에밋 시어(Emmett Shear)조차 '해리포터와 이성의 길'에 자신의 이름이 캐릭터로 새겨져 있다는 사실에 매우 기뻐했다. 자신의 '생일 선물'이라고 했다.
이 소설의 저자는 AI 연구자 Eliezer Yudkowsky입니다.
다소 생소한 이름이지만 소셜 네트워크를 통해 보면 피터 티엘(Peter Thiel), 샘 알트만(Sam Altman), 폴 그레이엄(Paul Graham)과 긴밀한 관계를 맺고 있음을 알 수 있다.
"해리포터와 이성의 길"에서 우리에게 친숙한 해리는 삼촌으로 변합니다. 더 이상 그를 하루 종일 때리고 꾸짖는 버논 더즐리가 아니라 옥스포드 대학의 교수로 변합니다.
이 세상의 해리는 어린 시절부터 집에서 교육을 받았으며 과학과 합리적 사고를 좋아합니다. 마법의 세계에 입문한 후, 해리는 합리적이고 과학적인 정신으로 마법을 탐구하기 위해 자연스럽게 래번클로 하우스에 배정되었습니다.

많은 사람들이 어릴 때 이 소설을 읽고 EA를 이해하기 시작했고, 이를 통해 인공지능 분야에 진출하려는 의지도 강해졌습니다.
아마도 우리가 EA나 e/acc 중 하나를 선택하든지, 우리는 모두 "마법의" AI 기술의 원리를 밝히기 위해 노력하는 시대에 살고 있습니다.
"저주를 잊는 것"부터 시작하겠습니다.
모든 AI 연구자들이 해리의 친절함, 용기, 절제를 기억할 수 있기를 바랍니다.
# aifaner 공식 위챗 공개 계정: aifaner(WeChat ID: ifanr) 팔로우를 환영합니다. 더 흥미로운 콘텐츠는 최대한 빨리 제공해 드리겠습니다.
Ai Faner | 원본 링크 · 댓글 보기 · Sina Weibo